”tensorflow vqa question-answering attention clevr machine-reasoning compositional-attention-networks TensorflowPython“ 的搜索结果

TensorFlow版本:1.9.0 Keras版本:2.0.2 我的博客: :
本文主要介绍了大模型加速库flash-attention的安装教程,希望能对使用flash-attention的同学们有所帮助。 文章目录 1. 背景描述 2. 逐步安装教程
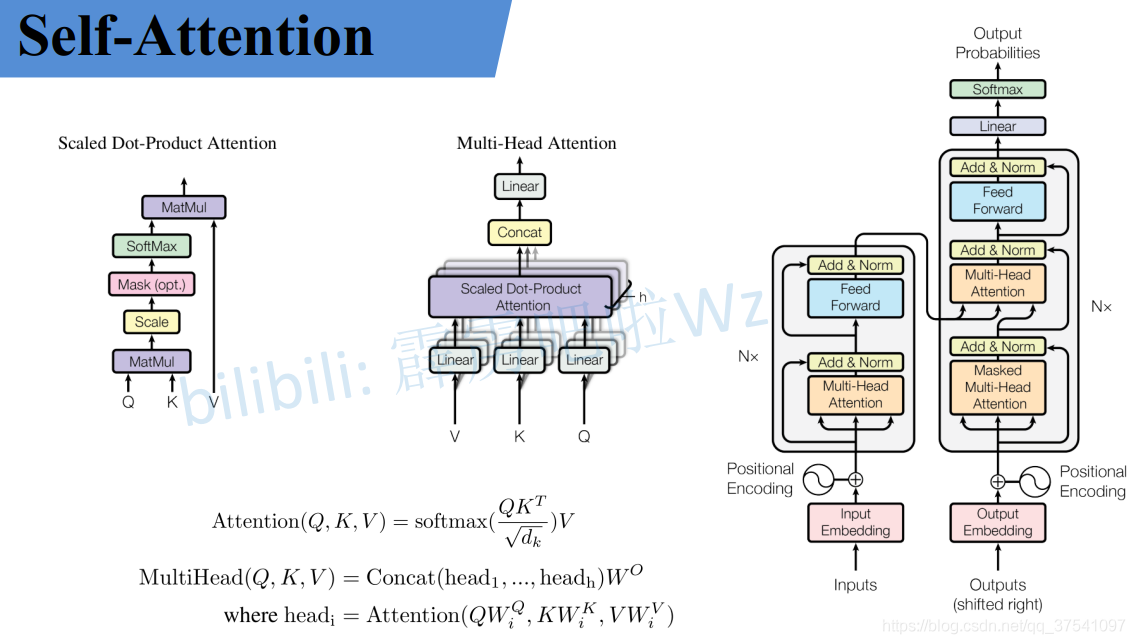
1. self-attention原理介绍 形象化解释:The Illustrated Transformer 哈佛代码介绍:The Annotated Transformer 论文解读:Attention Is All You Need - The Transformer 2. self-attention改进方向 先放资源,...

结构注意 新颖的神经网络体系结构设计用于对结构规则进行建模,而不是在变压器中发现规则的自我关注,这可以改善对不同长度序列的外推,这反过来又可以改善整体性能。 开发该项目是为了更好地关注模型的概念证明。...
多维时序 | MATLAB实现CNN-LSTM-Attention多变量时间序列预测
当我们理解attention 和self-attention 后就可以学习transformer模型,BERT 了。可以看出在当前NLP领域attention 机制的重要性。
Self-Attention自注意力机制是Transformer模块的重要组成部分,是截至到现在(2024年1月6日)大大小小网络的标配,无论是LLM还是StableDiffusion,内部都有Self-Attention与Transformer,因此,一起来学学哈哈。
分类预测 | MATLAB实现CNN-LSTM-Attention多输入分类预测
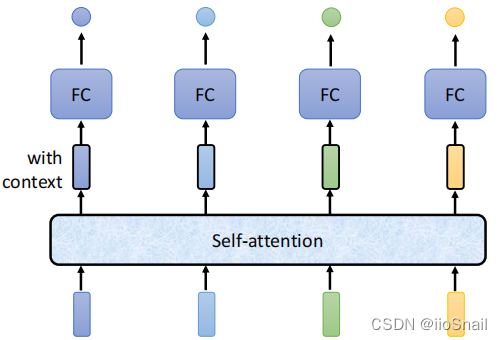
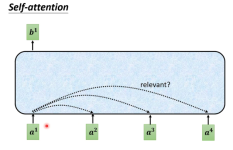
1 Self-Attention的概念2 Self-Attention的原理3 Self-Attention的作用4 Self-Attention的问题。


对于《Attention is all you need》这篇文章中提到的transformer模型,自己最初阅读的时候并不是很理解,于是决定从头开始,一点一点梳理transformer模型。这篇论文主要亮点在于: (1)不同于以往主流机器翻译使用...




回归预测 | MATLAB实现CNN-LSTM-Attention多输入单输出回归预测

2019-04-22 16:20:36 哈喽,大家好!我,人称神秘小马哥又回来了,不知道大家还记不记得上期我的秘密三叉戟,轻松力压股市三大指数。 ...这期我给大家解密一下我三叉戟的第一根利器,LSTM模型,它在股价预测中更...
关于self-attention的基本定义,以及在自然语言处理方向的发展,参考 1、图像识别方向 Non-local Neural Networks 论文将self-attention抽象成为了一个如同卷积、循环操作类似的通用神经网络构件non-local,并主要...





推荐文章
- Python菜鸟晋级04----raw_input() 与 input()的区别_pycharm没有raw input-程序员宅基地
- 高通AR增强现实多卡识别和扩展跟踪Unity_imagetarget扩展追踪-程序员宅基地
- 对于三星手机的手工root方法-程序员宅基地
- 2021年佛山高考成绩查询,2021年高三佛山一模,看佛山高中排名-程序员宅基地
- 删除并清空应收应付模块 期初数据_应付管理系统怎么清除数据-程序员宅基地
- 嵌入式固件加密的几种方式-程序员宅基地
- 非root情况下访问手机存储位置权限的方法_不root 通讯录 存放目录-程序员宅基地
- Mybatis项目开发流程_使用mybatis的开发步骤-程序员宅基地
- 三方协议,档案,工龄,保险,户口,-程序员宅基地
- 华为交换机命令 端口速率_华为S5700交换机的端口QOS限速问题-程序员宅基地